
作者:Marco Bonzanini 翻译:数盟
这是7部系列中的第1部分,注重挖掘Twitter数据以用于各种案例。这是第一篇文章,专注于数据采集,起到奠定基础的作用。
Twitter是一个流行的社交网络,用户可以共享称为tweets的类似SMS的短消息。用户在Twitter上分享想法、链接和图片,记者发表现场活动评论,企业改进产品和吸引客户等等。使用Twitter的不同的方式列表可能会很长,伴随着每天5亿的tweets,这里有大量的数据等着我们分析。
这是一系列使用Python专门用于Twitter数据挖掘的文章中的第一篇。在第一部分中,我们将看到通过不同的方式来进行Twitter的数据收集。一旦我们建立好了一个数据集,在接下来的环节中,我们就将会讨论一些有趣的数据应用。
注册应用
为了能够访问Twitter数据编程,我们需要创建一个与Twitter的API交互的应用程序。
第一步是注册一个你的应用程序。值得注意的是,您需要将您的浏览器转到http://apps.twitter.com,登录到Twitter(如果您尚未登录),并注册一个新的应用程序。您现在可以为您的应用程序选择一个名称和说明(例如“挖掘演示”或类似)。您将收到一个消费者密钥和消费者密码:这些都是应用程序设置,应始终保密。在您的应用程序的配置页面,你也可以要求获取一个访问令牌和访问令牌的密码。类似于消费者密钥,这些字符串也必须保密:他们提供的应用程序是代表您的帐户访问到Twitter。默认权限是只读的,这是我们在案例中需要的,但如果你决定改变您的许可,在应用中提供更改功能,你就必须再获得一个新的访问令牌。
重要提示:使用Twitter的API时有速率限制,或者你想要提供一个可下载的数据集也会有限制,请参见: >
您可以使用 Twitter提供的REST APIs与他们的服务进行交互。那里还有一群基于Python的客户,我们可以重复循环使用。尤其Tweepy是其中最有趣和最直白的一个,所以我们一起把它安装起来:

安装
更新:Tweepy发布的3.4.0版本在Python3上出现了一些问题,目前被绑定在GitHub上还不能进行使用,因此在新的版本出来之前,我们一直使用3.3.0版本。
更多的更新:Tweepy发布的3.5.0版本已经可以使用,似乎解决了上述提到的在Python3上的问题。
为了授权我们的应用程序以代表我们访问Twitter,我们需要使用OAuth的界面:界面

现在的API变量是我们为可以在Twitter上执行的大多数操作的入口点。
例如,我们可以看到我们自己的时间表(或者我们的Twitter主页):时间表

Tweepy提供便捷的光标接口,对不同类型的对象进行迭代。在上面的例子中我们用10来限制我们正在阅读的tweets的数量,但是当然其实我们是可以访问更多的。状态变量是Status() class的一个实例,是访问数据时一个漂亮的包装。Twitter API的JSON响应在_json属性(带有前导下划线)上是可用的,它不是纯JSON字符串,而是一个字典。
所以上面的代码可以被重新写入去处理/存储JSON:处理存储

如果我们想要一个所有用户的名单?来这里:名单

那么我们所有的tweets的列表呢? 也很简单:列表

通过这种方式,我们可以很容易地收集tweets(以及更多),并将它们存储为原始的JSON格式,可以很方便的依据我们的存储格式将其转换为不同的数据模型(很多NoSQL技术提供一些批量导入功能)。
process_or_store()功能是您的自定义实施占位符。最简单的方式就是你可以只打印出JSON,每行一个tweet:打印

流
如果我们要“保持连接”,并收集所有关于特定事件将会出现的tweets,流API就是我们所需要的。我们需要扩展StreamListener()来定义我们处理输入数据的方式。一个用#python hashtag收集了所有新的tweet的例子:案例
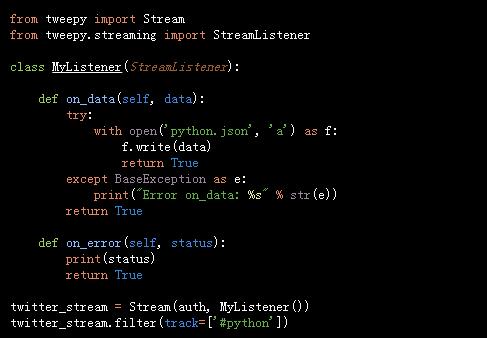
根据不同的搜索词,我们可以在几分钟之内收集到成千上万的tweet。世界性覆盖的现场活动尤其如此(世界杯、超级杯、奥斯卡颁奖典礼等),所以保持关注JSON文件,看看它增长的速度是多么的快,并考量你的测试可能需要多少tweet。以上脚本将把每个tweet保存在新的行中,所以你可以从Unix shell中使用wc-l python.json命令来了解到你收集了多少tweet。
你可以在下面的要点中看到Twitter的API流的一个最小工作示例:
twitter_stream_downloader.py
总结
我们已经介绍了tweepy作为通过Python访问Twitter数据的一个相当简单的工具。我们可以根据明确的“tweet”项目目标收集一些不同类型的数据。
一旦我们收集了一些数据,在分析应用方面的就可以进行展开了。在接下来的内容中,我们将讨论部分问题。
简介:Marco Bonzanini是英国伦敦的一个数据科学家。活跃于PyData社区的他喜欢从事文本分析和数据挖掘的应用工作。他是“用Python掌握社会化媒体挖掘”( 2016月7月出版)的作者。